Research Area
Explore the main research directions currently pursued at Smart Sound Lab.
Research Areas

Speech Enhancement / Separation
With the recent rising of live streaming services such as YouTube, outdoor recording is frequently observed in public. In particular, multichannel recording outdoor is commonly utilized to provide immersive audio to an audience beyond the screen. However, since outdoor recording inevitably entails ambient noise, ambient noise must be suppressed to make the desired speech heard well.
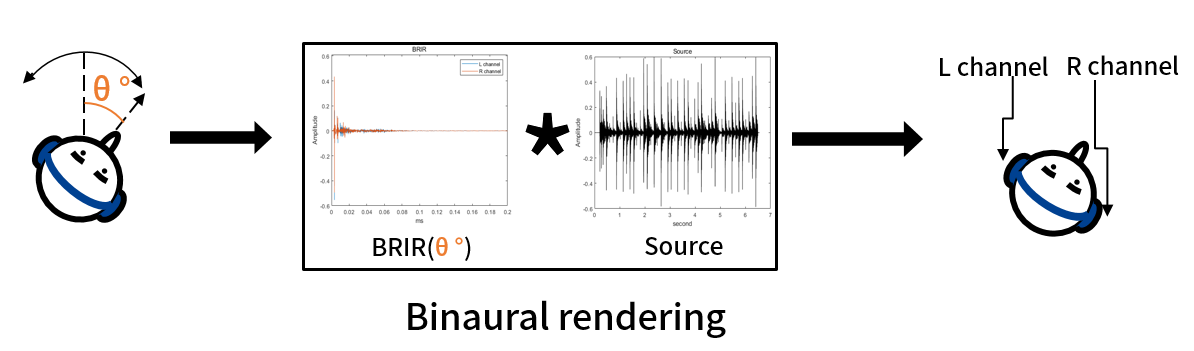
Binaural Rendering
Recently, with the emergence of Apple's spatial audio technology and Meta's AR/VR devices, technologies that render virtual audio as if it were actually present in the real world are gaining traction. Virtual audio for AR/VR devices is played through headphones. However, it is challenging to provide a sense of reality and spatiality, through audio played via headphones.
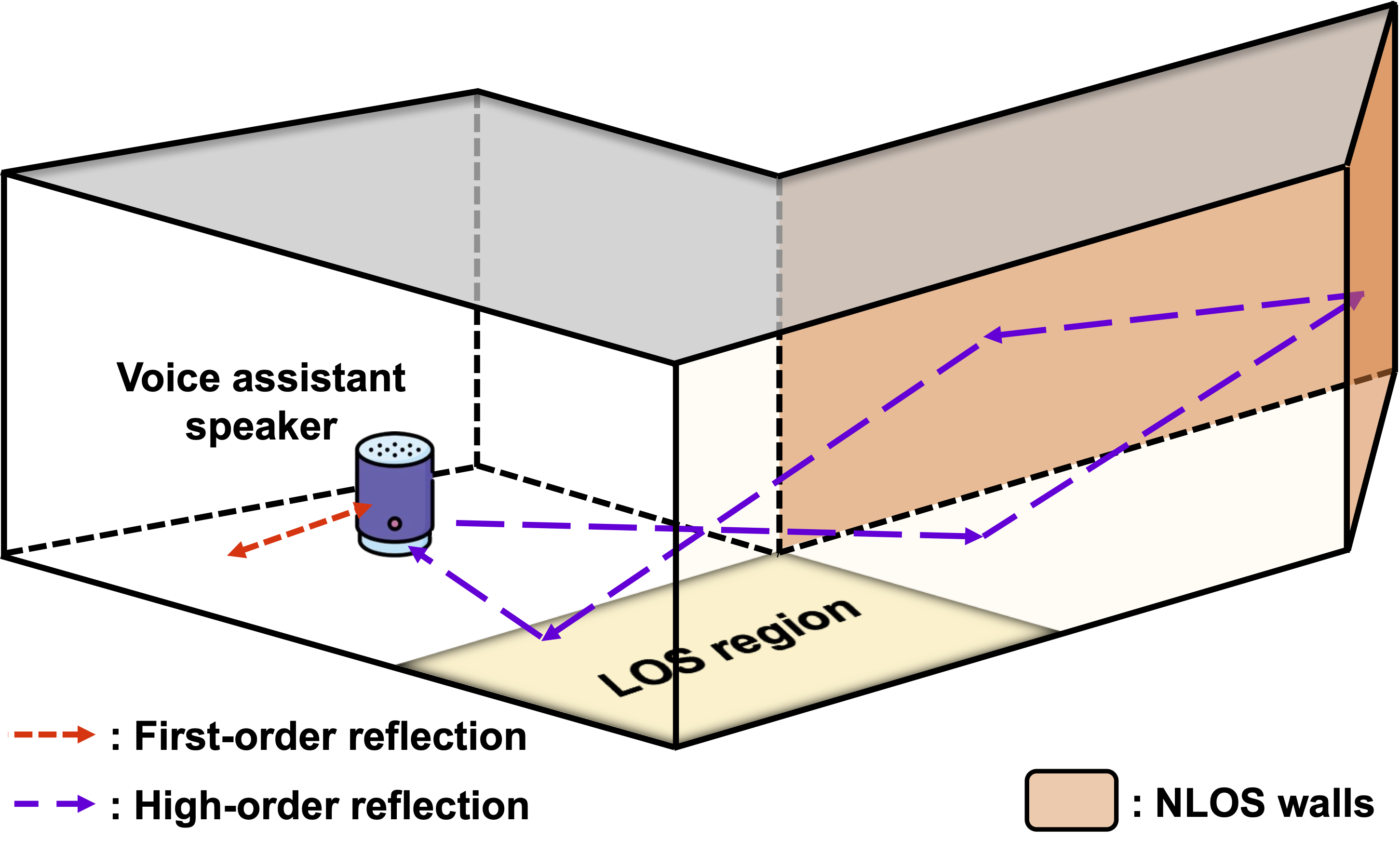
Room Geometry Inference
Estimating indoor geometries is a crucial step in creating realistic digital twins of indoor spaces. Traditionally, methods to determine indoor geometries relied on vision-based techniques. However, creating an accurate digital twin becomes challenging when the camera-captured indoor image has hidden areas in the scene.
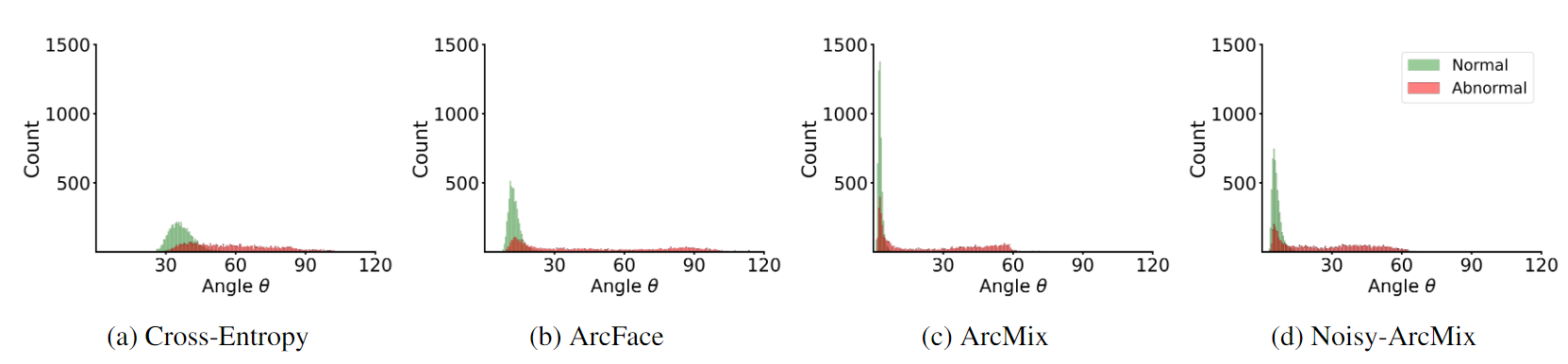
Anomaly Detection
Anomalous sound detection enhances maintenance efficiency in industries by early detecting equipment malfunctions, ensuring swift responses to security incidents, aiding in accident prevention in transportation, and contributing to noise management and emergency response in urban environments.
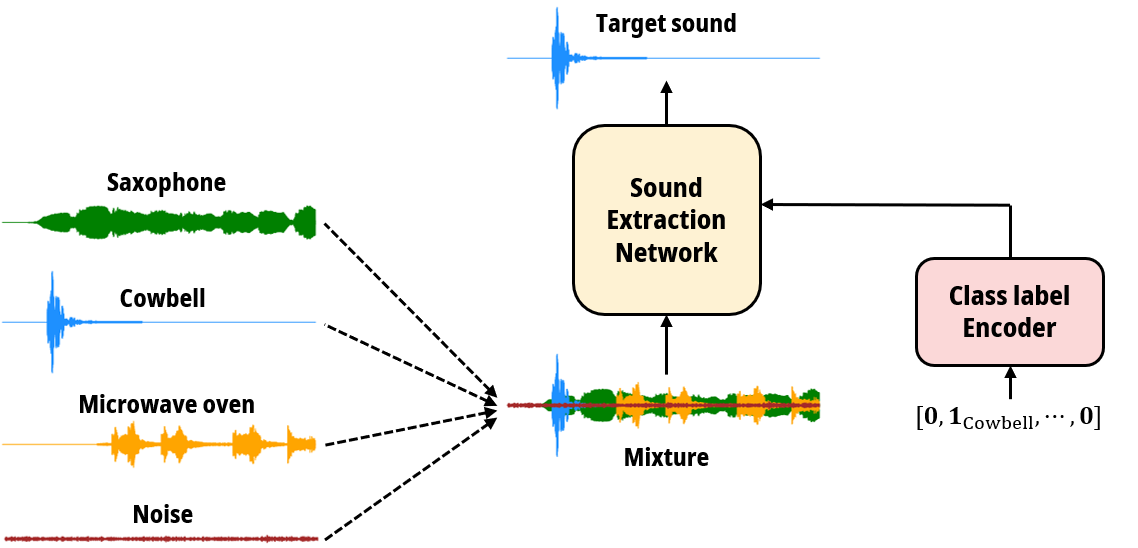
Target Sound Extraction
Imagine yourself in a bustling café, eager to hear your friend's speech amid the mixture of music, keyboard clatter, and ambient noise. Your brain effortlessly filters through these sounds, focusing solely on your friend's speech, aided by clues like their appearance and direction. What if we could train a deep learning model to do the same? Our research is dedicated to harnessing the potential of deep learning algorithms to precisely extract a specific sound from a complex audio mixture, regardless of its composition.
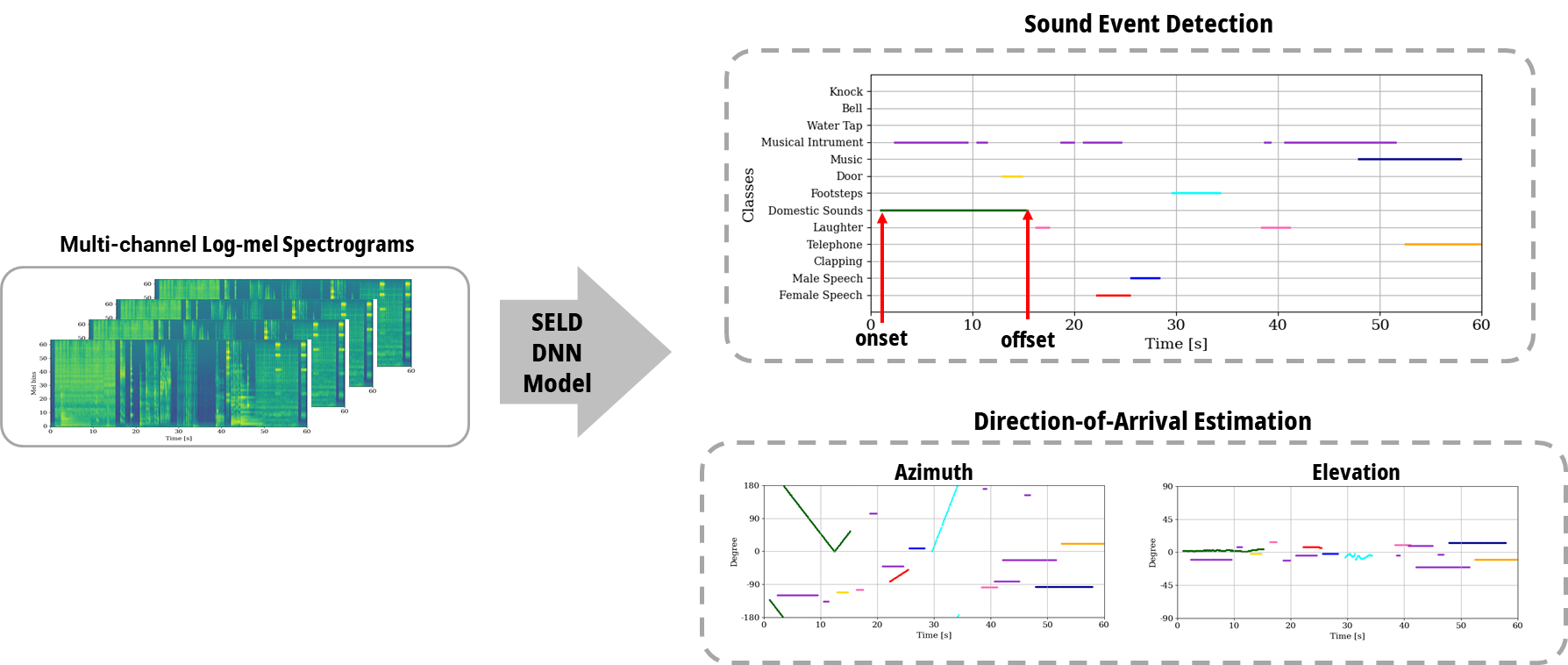
Sound Event Localization & Detection
Sound event localization and detection (SELD) is a task classifying sound events and localizing the direction-of-arrival (DoA) utilizing multi-channel acoustic signals. Sound event detection is to detect the onset and offset of audio of each class, therefore, making spectral and temporal information important. Localization of DoA is to specify the azimuth and elevation of the DoA of the audio source in the temporal domain, which requires additional spatial information with microphone multi-channel information. Although the spatial, spectral, and temporal information is crucial for the SELD task, prior studies employ spectral and channel information as the embedding for temporal attention learning temporal context. This usage limits the deep neural network from extracting meaningful features from the spectral or spatial domains. Therefore, we propose a novel framework termed the Channel-Spectro-Temporal Transformer (CST-former) that bolsters SELD performance by independently applying attention mechanisms to distinct domains, enabling deep neural network (DNN) to learn contexts of space, frequency, and time.