Drone sound dataset
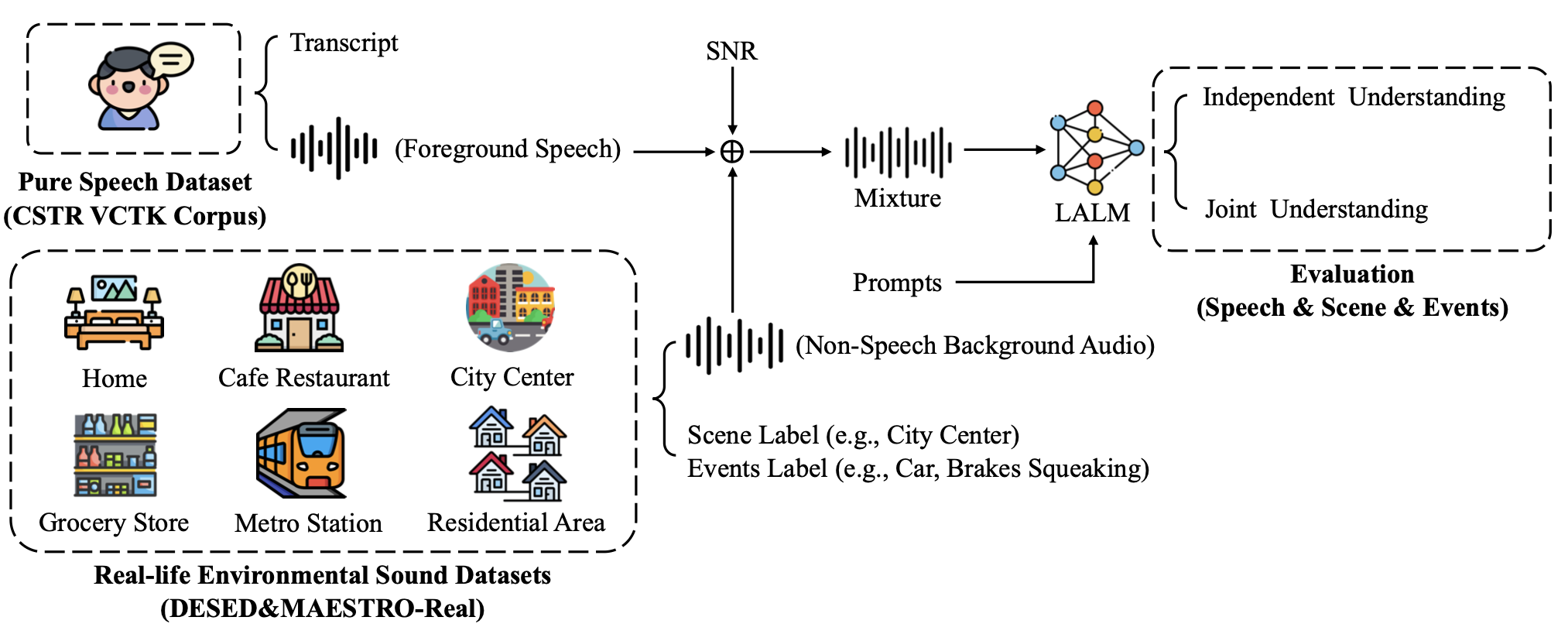
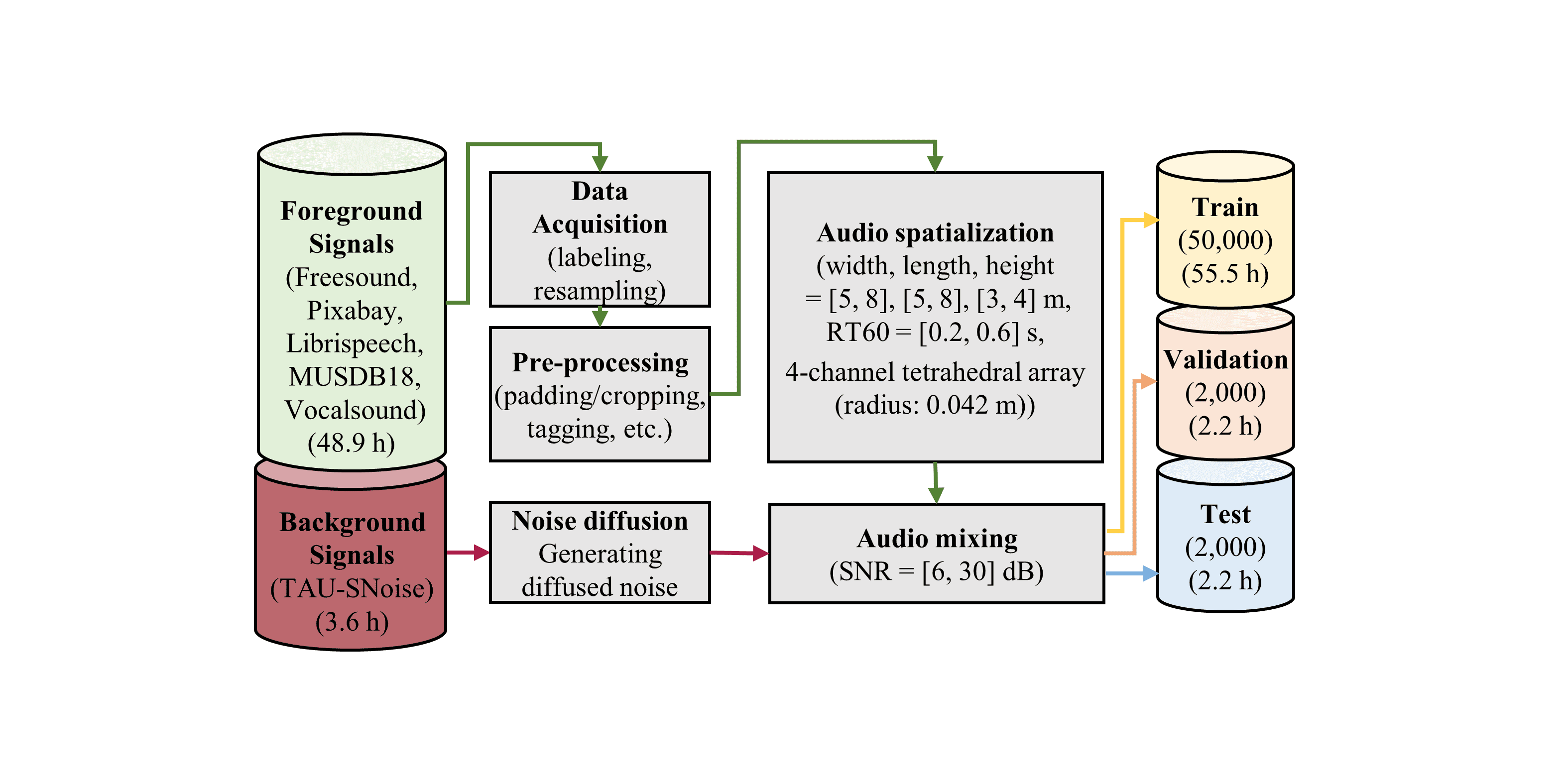
Wonjun Yi; Jung-Woo Choi; Jae-Woo Lee arxiv : https://arxiv.org/abs/2304.11708 Accepted at 29th International Congress on Sound and Vibration (ICSV29). To improve the safety of drone operations, one should detect the mechanical faults of drones in real-time. The drone sound dataset was constructed by collecting the operating sounds of drones from microphones mounted on three different drones in an anechoic chamber. The dataset includes various operating conditions of drones, such as flight directions (front, back, right, left, clockwise, counterclockwise) and faults on propellers and motors. The drone sounds were then mixed with noises recorded in five different spots on the university campus, with a signal-to-noise ratio (SNR) varying from 10 dB to 15 dB.